
Sustainable Production with Guided Data Wrangling
2024-06-03
–
Data Transformation
A production line that comes to a halt due to defective parts is a significant cost factor. In such situations, time is of the essence to resume operations. Guided Data Wrangling helps to efficiently read, analyze, and quickly identify the source of errors in production data.
In the mass production of components – for instance, in the automotive industry – defective parts inevitably arise and are discarded. During this extensive production process, a root-cause analysis is initiated. The quality engineer traces the problem back through various production stages to locate the source of the error. This requires an overview and insights into the entire value chain, both of which are provided by data.
In many cases, the quality engineer still personally collects data from the machines. They read sensor and measurement data, record it in an Excel sheet, and attempt to consolidate it into a unified data set. This manual process is time-consuming and can introduce new errors, as machines may use different formats for dates and times. Thus, data must be standardized before analysis to yield valid results. Consequently, the quality manager spends a considerable amount of time – sometimes days – preparing the data for meaningful analysis. Often, historical data from IT is also needed for comparison, which costs valuable time and money.
In many cases, the quality engineer still personally collects data from the machines. They read sensor and measurement data, record it in an Excel sheet, and attempt to consolidate it into a unified data set. This manual process is time-consuming and can introduce new errors, as machines may use different formats for dates and times. Thus, data must be standardized before analysis to yield valid results. Consequently, the quality manager spends a considerable amount of time – sometimes days – preparing the data for meaningful analysis. Often, historical data from IT is also needed for comparison, which costs valuable time and money.
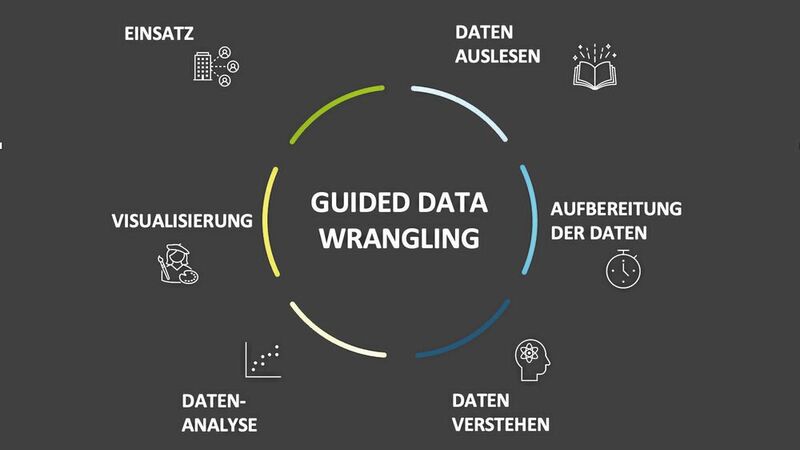
Data Wrangling is an IT process focused on preparing datasets. (Image: thaltegos)
Reliable Data at the Push of a Button
Data Wrangling is an IT process where raw data from various sources and formats is automatically and meaningfully prepared into a single dataset for further processing. Guided Data Wrangling aims to introduce every on-site quality manager to Data Wrangling through standardized processes.
The package includes modules that identify data gaps and outliers, cleansing the data to make it suitable for further analysis. It also integrates elements for networking information and establishing standardized data structures. Consequently, the quality engineer no longer needs to visit each machine to read data. Their Excel sheets, the time-consuming data alignment, and the need to ask IT for additional relevant information are eliminated. Another advantage is that no deep data expertise is required.
The package includes modules that identify data gaps and outliers, cleansing the data to make it suitable for further analysis. It also integrates elements for networking information and establishing standardized data structures. Consequently, the quality engineer no longer needs to visit each machine to read data. Their Excel sheets, the time-consuming data alignment, and the need to ask IT for additional relevant information are eliminated. Another advantage is that no deep data expertise is required.
Analysis Modules Quickly Identify Error Sources
To conduct a root-cause analysis after a production error using Guided Data Wrangling, the quality manager controls the entire process through a graphical interface. In the first step, they use a drag-and-drop system to compile the necessary datasets from the production stages to find a specific error in manufacturing. These data connection points run through standard interfaces. The data is then loaded into a local or web environment, enabling the evaluation of these production data.
Often, many employees lack deep knowledge of data analytics. Therefore, Guided Data Wrangling provides industry-specific components for typical production analyses, examples of workflows, frameworks, or modular toolsets. This way, they can draw the correct insights from the data. It’s like a library of relevant modules used depending on the production or defect situation. This allows for targeted analyses, which can quickly resolve production deviations. After all, no one knows the production process better than the engineers on site. They know from experience which data and pre-configured analysis tools to choose to get closer to the problem.
The data volumes generated in industrial production are significant. Therefore, a meaningful visualization of the data and analysis results – tailored to the manufacturing industry – is indispensable for quality engineers to make the right decisions to reduce defects. The system also takes care of this.
Due to the many available modules, Guided Data Wrangling offers the quality engineer a great deal of flexibility. Additionally, the analysis tools can be used for all production lines with their specific issues and products.
Often, many employees lack deep knowledge of data analytics. Therefore, Guided Data Wrangling provides industry-specific components for typical production analyses, examples of workflows, frameworks, or modular toolsets. This way, they can draw the correct insights from the data. It’s like a library of relevant modules used depending on the production or defect situation. This allows for targeted analyses, which can quickly resolve production deviations. After all, no one knows the production process better than the engineers on site. They know from experience which data and pre-configured analysis tools to choose to get closer to the problem.
The data volumes generated in industrial production are significant. Therefore, a meaningful visualization of the data and analysis results – tailored to the manufacturing industry – is indispensable for quality engineers to make the right decisions to reduce defects. The system also takes care of this.
Due to the many available modules, Guided Data Wrangling offers the quality engineer a great deal of flexibility. Additionally, the analysis tools can be used for all production lines with their specific issues and products.
Guided Data Wrangling Saves Many Resources
The system can be understood as a kind of self-service program or a co-pilot for the quality manager to quickly address production errors. It is crucial that production data and analysis options are easily accessible, democratically and decentralized for all involved. This brings autonomy and speed to the daily routine of quality engineers.
Identifying and quickly correcting malfunctions is only one goal of Guided Data Wrangling. To avoid defects from the outset, current manufacturing information should continuously flow into the data base. This gives quality managers the opportunity to continuously monitor their production through standard analyses, allowing them to detect and eliminate weaknesses in the production process early on.
Moreover, the analysis modules can also be linked with artificial intelligence (AI). When a machine learning (ML) layer is applied to the data base, AI can assist in this automated process to identify potential error sources in advance.
The benefits of Guided Data Wrangling are clear: the approach brings together heterogeneous datasets automatically and quickly for further analysis and optimization of production lines. Additionally, it ensures smooth and forward-looking component production. This saves the company time, money, and – in line with the general sustainability concept – material.
Identifying and quickly correcting malfunctions is only one goal of Guided Data Wrangling. To avoid defects from the outset, current manufacturing information should continuously flow into the data base. This gives quality managers the opportunity to continuously monitor their production through standard analyses, allowing them to detect and eliminate weaknesses in the production process early on.
Moreover, the analysis modules can also be linked with artificial intelligence (AI). When a machine learning (ML) layer is applied to the data base, AI can assist in this automated process to identify potential error sources in advance.
The benefits of Guided Data Wrangling are clear: the approach brings together heterogeneous datasets automatically and quickly for further analysis and optimization of production lines. Additionally, it ensures smooth and forward-looking component production. This saves the company time, money, and – in line with the general sustainability concept – material.
* Dr. Michael Wolff is a partner at the management consultancy Thaltegos, specializing in Data Analytics and Artificial Intelligence, and part of the Plan.Net Group.
Hero image by carlos aranda at Unsplash
Hero image by carlos aranda at Unsplash
Contact
Get in touch.
For inquiries or requests, please, feel free to contact us. We will respond in a timely manner.

